

Teknikvärlden är fortfarande fängslad av den pågående kampen mellan GPU-titaner inom högpresterande databehandling (HPC), där hastighet och effektivitet är av största vikt. I spetsen för denna hårda konkurrens har NVIDIAs Tensor Core GPU:er revolutionerat landskapet, flyttat fram gränserna för beräkningskraft och öppnat nya horisonter för vetenskaplig forskning, artificiell intelligens och dataintensiva applikationer.
I den här bloggen fördjupar vi oss i den spännande kraftmätningen mellan två framstående NVIDIA GPU:er, A100 och H100, belyser deras unika kapacitet och utforskar betydelsen av deras jämförelse. Dessa banbrytande GPU:er har omdefinierat vad som är möjligt inom HPC och utnyttjar avancerad teknik för att ge oöverträffad prestanda och skalbarhet.
NVIDIA A100 vs H100 Jämförelsetabell för tekniska specifikationer
| Funktion | NVIDIA A100 | NVIDIA H100 |
|---|---|---|
| Arkitektur | Ampere | Hopper |
| CUDA-kärnor | 6,912 | 18,432 |
| Tensor-kärnor | 432 (3:e generationen) | 640 (4:e generationen) med transformatormotor |
| Minne | 40 GB / 80 GB HBM2e | 80 GB HBM3 |
| Bandbredd för minne | 2,0 TB/s | 3,35 TB/s |
| FP32-prestanda | ~19,5 TFLOPS | ~51 TFLOPS |
| FP8-prestanda | Stödjs inte | Över 2.000 TFLOPS |
| NVLink | NVLink 3.0 (600 GB/s) | NVLink 4.0 (900 GB/s) |
| GPU med flera instanser (MIG) | 1:a generationens MIG (upp till 7 instanser) | 2:a generationens MIG |
| PCIe strömförbrukning | ~250W | ~350W |
| SXM Strömförbrukning | ~400W | ~700W |
Specifikationer och kapacitet för NVIDIA A100
NVIDIA A100, baserad på Ampere-arkitekturen, ger betydande framsteg jämfört med den tidigare Volta-generationen. A100 är utrustad med 6 912 CUDA-kärnor, 432 tredje generationens Tensor-kärnor och 40 GB eller 80 GB HBM2e-minne med hög bandbredd och är konstruerad för högpresterande AI-arbetsbelastningar. Den erbjuder upp till 20× snabbare prestanda jämfört med tidigare GPU:er i specifika mixed-precision-uppgifter.
Benchmark-resultat visar på dess styrka inom deep learning-applikationer, inklusive bildigenkänning, NLP (Natural Language Processing) och taligenkänning.
En viktig innovation i Ampere-arkitekturen är tredje generationens Tensor Cores, som är optimerade för matrisoperationer med hög kapacitet i format som TF32 och FP16. A100 introducerar också NVIDIA Multi-Instance GPU (MIG)-teknik, som gör att en enda GPU kan delas upp i upp till sju isolerade instanser.
Specifikationer och kapacitet för NVIDIA H100
NVIDIA H100 GPU, som bygger på Hopper-arkitekturen, levererar banbrytande prestanda för AI- och HPC-arbetsbelastningar. Den har 18 432 CUDA-kärnor, 640 fjärde generationens Tensor-kärnor och 80 Streaming Multiprocessors (SM). H100 ger upp till 51 teraflops FP32-prestanda och över 2 000 teraflops med FP8-precision.
Den integrerar NVLink 4.0 för upp till 900 GB/s GPU-till-GPU-bandbredd och stöder nästa generations arbetsbelastningar som stora språkmodeller och djupa neurala nätverk.
I branschjämförelser som MLPerf överträffar H100 A100 och V100 avsevärt.
Jämförelse av prestandabaserade riktmärken (MLPerf eller arbetsbelastningsbaserad)
| Typ av arbetsbelastning | A100 Prestanda | H100 Prestanda | Förbättring |
|---|---|---|---|
| BERT-inferens | 1× | 3.5-4× | Upp till 4× |
| GPT-3-utbildning | 1× | 2-3× | 2-3× |
| ResNet-50 Utbildning | 1× | 2.2× | 2.2× |
| Vetenskaplig simulering (FP64) | 1× | 2× | 2× |
Arkitektoniska skillnader mellan A100 och H100
A100 använder HBM2e-minne (40/80 GB) med en bandbredd på 2,0 TB/s. H100 går upp till HBM3 (80 GB) och 3,35 TB/s bandbredd. H100 innehåller fjärde generationens Tensor-kärnor och FP8-precision, som drivs av en Transformer Engine.
Båda har stöd för MIG, men H100:s 2:a generationens MIG ger bättre isolering och effektivitet.
Jämförelse av strömeffektivitet
H100 GPU drar mer ström än A100 - upp till 700 W i SXM-formfaktor jämfört med 400 W för A100. Den ökade strömförbrukningen åtföljs dock av betydligt bättre prestanda, särskilt i arbetsbelastningar som är optimerade för FP8-precision och Transformer Engine.
När man jämför prestanda per watt med hjälp av standardiserade riktmärken som MLPerf (t.ex. ResNet-50-träning), ger H100 cirka 60% högre effektivitet än A100. Det innebär att även om H100 förbrukar mer energi, utför den också mer arbete per förbrukad energienhet.
När det gäller kylning kräver H100 mer robust termisk hantering på grund av sin högre effekttäthet, men moderna datacenter är i allmänhet utrustade för att hantera detta. Effektivitetsvinsterna motiverar de extra kylningskraven i prestandakritiska miljöer.
Scenarier för bästa användningsfall (tabellvy)
| Typ av användningsfall | Bästa valet | Varför |
|---|---|---|
| Allmän utbildning i djupinlärning | A100 | Stark prestanda, kostnadseffektivt |
| Träning av stora språkmodeller | H100 | FP8 + Transformer Engine, utmärkt genomströmning |
| Inferens i realtid | H100 | Låg latens, snabb minnesåtkomst |
| Vetenskapliga simuleringar | H100 | Bättre FP64 och bandbredd |
| Budgetmedvetna AI-projekt | A100 | Mer prisvärd, allmänt tillgänglig |
| Miljöer med flera hyresgäster | Båda | H100 har bättre MIG; A100 är mer ekonomisk |
Pris- och tillgänglighetsjämförelse A100 Vs H100
Medan H100 klart överträffar A100 när det gäller rå beräkningskraft, har den också en betydligt högre kostnad - både när det gäller återförsäljningsvärde för hårdvara och molnhyra per timme. För att illustrera avvägningarna mellan kostnad och kapacitet visar följande visuella jämförelser hur A100 och H100 står sig i tre viktiga dimensioner: prissättning på återförsäljningsmarknaden, molndriftskostnader och normaliserad AI-prestanda.
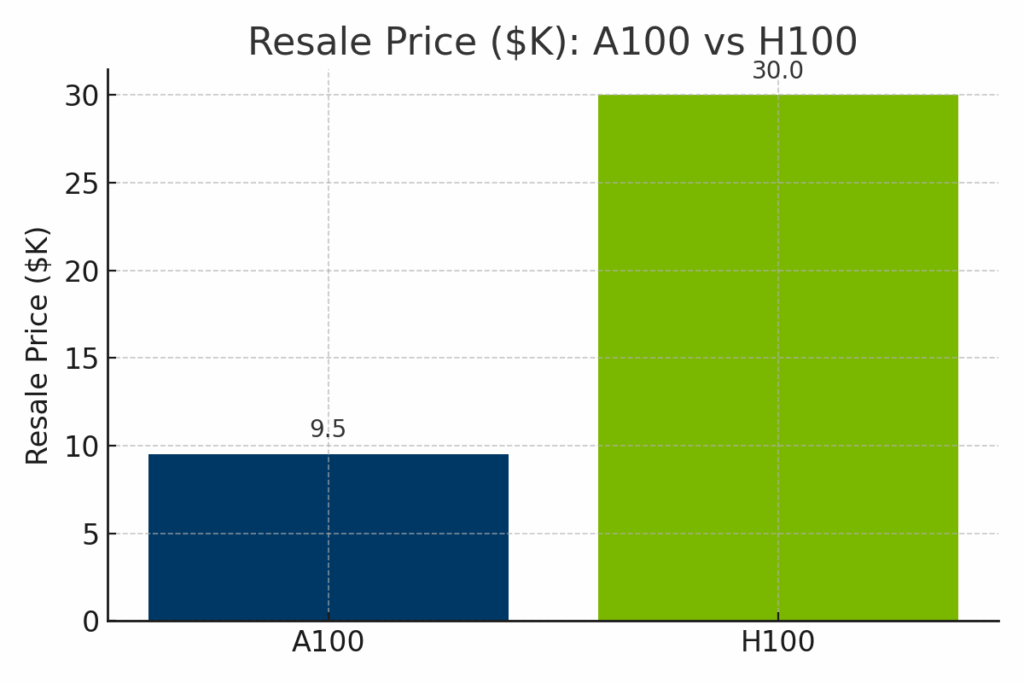
Figur: Uppskattat återförsäljningsvärde för NVIDIA A100 jämfört med H100 år 2025. H100 har ett betydligt högre återförsäljningspris - i genomsnitt cirka $30 000 - på grund av sin nyare arkitektur och banbrytande prestanda, medan A100 vanligtvis säljs för $9 000-$12 000.
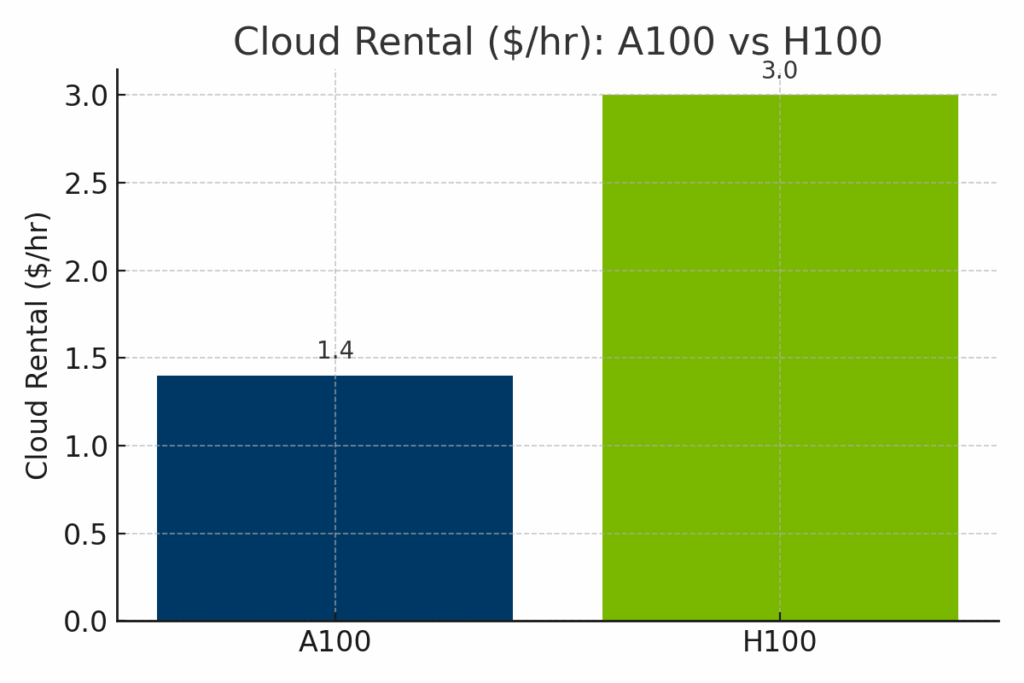
Diagram: Hyrespriser per timme i molnet för A100- och H100-GPU:er hos större leverantörer. H100-instanser kostar betydligt mer - ofta runt $3,00/timme - jämfört med A100:s genomsnitt på $1,40/timme, vilket återspeglar H100:s förbättrade AI-genomströmning och nyare efterfrågan på infrastruktur.
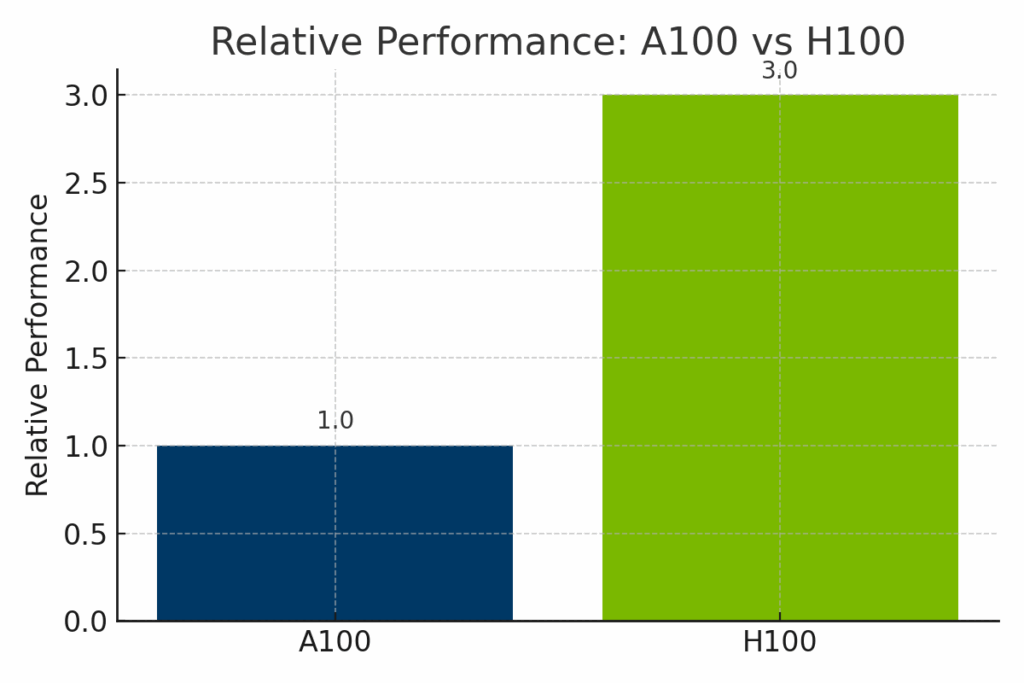
Bild: Normaliserad prestanda för NVIDIA A100 och H100 i olika AI-arbetsbelastningar. H100 levererar upp till 3× så hög prestanda som A100, särskilt i transformatorbaserade modeller och FP8-optimerad träning, vilket gör den idealisk för banbrytande AI i företag.
NVIDIA:s färdplan och framtida utveckling
NVIDIA:s framtida GPU:er, baserade på den kommande Blackwell-arkitekturen (t.ex. B100, B200), förväntas ge ännu större beräkningstäthet och minnesförbättringar.
NVIDIA:s mjukvaruplattformar som CUDA, TensorRT och AI Enterprise underhålls aktivt för att stödja nya arbetsbelastningar.
Ekosystem för programvara och stöd för utvecklare
Båda GPU:erna har stöd för CUDA, cuDNN, cuBLAS, TensorRT och populära ramverk som PyTorch, TensorFlow och JAX.
H100 drar nytta av förbättrat FP8-stöd och optimering av Transformer Engine inom dessa ekosystem. Utvecklare kan använda förbyggda behållare på NVIDIA NGC och robust dokumentation via NVIDIA Developer Program.
Sammanfattning av för- och nackdelar
| Kategori | NVIDIA A100 | NVIDIA H100 |
|---|---|---|
| Proffs | Kostnadseffektiv, tillförlitlig och stark för standard AI/HPC | Bästa prestanda, FP8, överlägsen för LLM och realtidsinferens |
| Nackdelar | Saknar nyare AI-funktioner (t.ex. FP8, Transformer Engine) | Högre kostnad, kraftintensiv, kan behöva uppgradering av infrastruktur |
| Idealisk för | Budgetmedvetna team, traditionell HPC, molnskalning | Avancerade AI-arbetsbelastningar, generativ AI, företagsdriftsättningar |
Att välja mellan A100 och H100 för AI-arbetsbelastningar
Valet mellan A100 och H100 beror på dina mål, din budget och ditt användningsområde. A100 är kostnadseffektivt och ändå kraftfullt för många AI/HPC-uppgifter. H100 är ett framtidsklart kraftpaket som är byggt för de mest krävande arbetsbelastningarna.
Om du uppgraderar till en nyare GPU som H100 kan du överväga att sälja din äldre maskinvara till exIT Technologies. Vi erbjuder säkra och effektiva tjänster för återvinning av tillgångar som hjälper dig att återvinna värde och hantera din pensionerade infrastruktur på ett ansvarsfullt sätt.



