

La communauté technologique reste captivée par la bataille permanente entre les titans du GPU dans le domaine du calcul haute performance (HPC), où la vitesse et l'efficacité sont primordiales. Au premier rang de cette compétition féroce, les GPU Tensor Core de NVIDIA ont révolutionné le paysage, repoussant les limites de la puissance de calcul et ouvrant de nouveaux horizons à la recherche scientifique, à l'intelligence artificielle et aux applications intensives en données.
Dans ce blog, nous nous penchons sur l'affrontement passionnant entre deux GPU NVIDIA de premier plan, le A100 et le H100, en mettant en lumière leurs capacités uniques et en explorant l'importance de leur comparaison. Ces GPU de pointe ont redéfini ce qui est possible dans le domaine du HPC, en s'appuyant sur des technologies avancées pour fournir des performances et une évolutivité sans précédent.
Tableau de comparaison des spécifications techniques entre le NVIDIA A100 et le H100
| Fonctionnalité | NVIDIA A100 | NVIDIA H100 |
|---|---|---|
| L'architecture | Ampère | Trémie |
| Cœurs CUDA | 6,912 | 18,432 |
| Cœurs de tenseur | 432 (3ème génération) | 640 (4ème génération) avec Transformer Engine |
| Mémoire | 40 GB / 80 GB HBM2e | 80 GB HBM3 |
| Largeur de bande de la mémoire | 2,0 To/s | 3,35 To/s |
| Performance FP32 | ~19,5 TFLOPS | ~51 TFLOPS |
| Performances du FP8 | Non pris en charge | Plus de 2 000 TFLOPS |
| NVLink | NVLink 3.0 (600 Go/s) | NVLink 4.0 (900 Go/s) |
| GPU multi-instances (MIG) | MIG de 1ère génération (jusqu'à 7 instances) | 2ème génération de MIG |
| Consommation d'énergie PCIe | ~250W | ~350W |
| Consommation électrique du SXM | ~400W | ~700W |
Caractéristiques et capacités de la NVIDIA A100
Le NVIDIA A100, basé sur l'architecture Ampere, apporte des avancées significatives par rapport à la génération Volta précédente. Équipé de 6 912 cœurs CUDA, de 432 cœurs Tensor de troisième génération et de 40 ou 80 Go de mémoire HBM2e à large bande passante, l'A100 est conçu pour les charges de travail d'IA de haute performance. Il offre des performances jusqu'à 20 fois supérieures à celles des GPU antérieurs pour des tâches spécifiques en précision mixte.
Les résultats des benchmarks mettent en évidence sa force dans les applications d'apprentissage profond, notamment la reconnaissance d'images, le traitement du langage naturel (NLP) et la reconnaissance vocale.
L'une des principales innovations de l'architecture Ampere est sa troisième génération de Tensor Cores, optimisée pour les opérations matricielles à haut débit utilisant des formats tels que TF32 et FP16. L'A100 introduit également la technologie NVIDIA Multi-Instance GPU (MIG), qui permet de partitionner un seul GPU en sept instances isolées.
Spécifications et capacités de la NVIDIA H100
Le GPU NVIDIA H100, basé sur l'architecture Hopper, délivre des performances de pointe pour les charges de travail d'IA et de HPC. Il comprend 18 432 cœurs CUDA, 640 cœurs Tensor de quatrième génération et 80 multiprocesseurs de streaming (SM). Le H100 offre jusqu'à 51 téraflops de performances en FP32 et plus de 2 000 téraflops en utilisant la précision FP8.
Il intègre NVLink 4.0 pour une bande passante GPU-to-GPU allant jusqu'à 900 Go/s et prend en charge les charges de travail de nouvelle génération telles que les grands modèles de langage et les réseaux neuronaux profonds.
Dans les benchmarks industriels tels que MLPerf, le H100 surpasse de manière significative l'A100 et le V100.
Comparaison des performances (MLPerf ou Workload-Based)
| Type de charge de travail | Performance de l'A100 | Performances du H100 | Amélioration |
|---|---|---|---|
| Inférence de l'ORET | 1× | 3.5-4× | Jusqu'à 4× |
| Formation GPT-3 | 1× | 2-3× | 2-3× |
| Formation ResNet-50 | 1× | 2.2× | 2.2× |
| Simulation scientifique (FP64) | 1× | 2× | 2× |
Différences architecturales entre A100 et H100
L'A100 utilise la mémoire HBM2e (40/80 Go) avec une bande passante de 2,0 To/s. Le H100 passe à la mémoire HBM3 (80 Go) avec une bande passante de 3,35 To/s. Le modèle H100 passe à la mémoire HBM3 (80 Go) et à une bande passante de 3,35 To/s. Le H100 comprend des Tensor Cores de quatrième génération et une précision FP8, alimentés par un Transformer Engine.
Les deux sont compatibles avec la technologie MIG, mais la deuxième génération MIG du H100 offre une meilleure isolation et une meilleure efficacité.
Comparaison de l'efficacité énergétique
Le GPU H100 consomme plus d'énergie que l'A100 - jusqu'à 700 W dans le format SXM contre 400 W pour l'A100. Cependant, cette consommation accrue s'accompagne d'une amélioration significative des performances, en particulier dans les charges de travail optimisées pour la précision FP8 et le Transformer Engine.
Lorsque l'on compare les performances par watt en utilisant des repères normalisés comme MLPerf (par exemple, formation ResNet-50), le H100 offre une efficacité supérieure d'environ 60% par rapport à l'A100. Cela signifie que même si le H100 consomme plus d'énergie, il accomplit également plus de travail par unité d'énergie consommée.
En termes de refroidissement, le H100 nécessite une gestion thermique plus robuste en raison de sa densité de puissance plus élevée, mais les centres de données modernes sont généralement équipés pour y faire face. Les gains d'efficacité justifient les exigences supplémentaires en matière de refroidissement dans les environnements où les performances sont critiques.
Scénarios de cas d'utilisation optimale (vue en tableau)
| Type de cas d'utilisation | Meilleur choix | Pourquoi |
|---|---|---|
| Formation générale à l'apprentissage profond | A100 | Des performances élevées, un bon rapport coût-efficacité |
| Formation de grands modèles linguistiques | H100 | FP8 + Transformer Engine, excellent débit |
| Inférence en temps réel | H100 | Accès rapide à la mémoire à faible latence |
| Simulations scientifiques | H100 | Meilleure FP64 et bande passante |
| Projets d'IA soucieux du budget | A100 | Plus abordable, plus largement disponible |
| Environnements multi-locataires | Les deux | Le H100 est plus performant en MIG ; le A100 est plus économique. |
Comparaison des prix et de la disponibilité du A100 et du H100
Si le H100 surpasse nettement l'A100 en termes de puissance de calcul brute, son coût est nettement plus élevé, tant en termes de valeur de revente du matériel qu'en termes de tarifs horaires de location de cloud. Afin d'illustrer les compromis entre coût et capacité, les comparaisons visuelles suivantes présentent les performances de l'A100 et du H100 selon trois dimensions clés : prix de revente sur le marché, coûts de déploiement dans le cloud et performances normalisées de l'IA.
Alors que le marché s'oriente vers l'architecture Hopper, il est nécessaire de trouver un partenaire fiable pour la mise en œuvre de l'architecture Hopper. Où vendre des cartes graphiques d'occasion comme l'A100 est essentiel pour optimiser votre budget et financer la transition vers une infrastructure d'IA plus avancée.
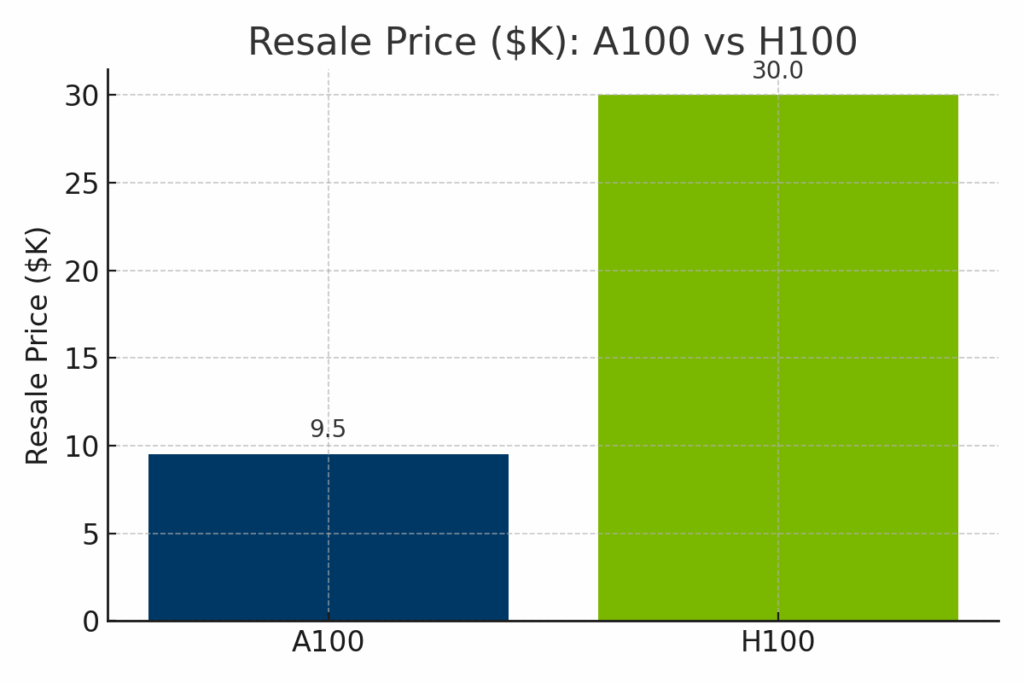
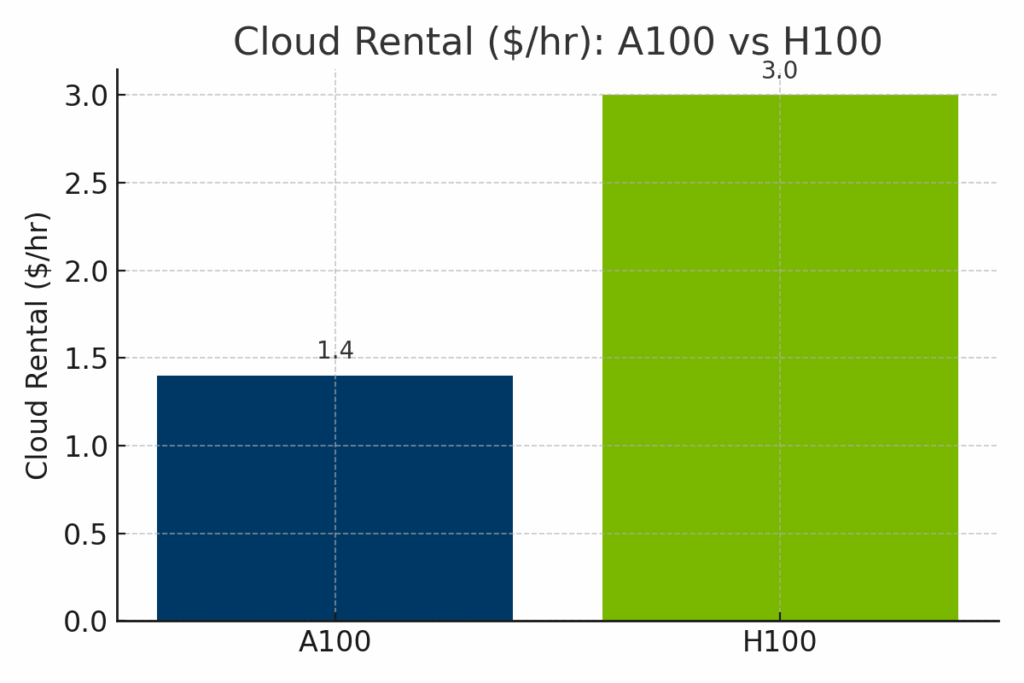
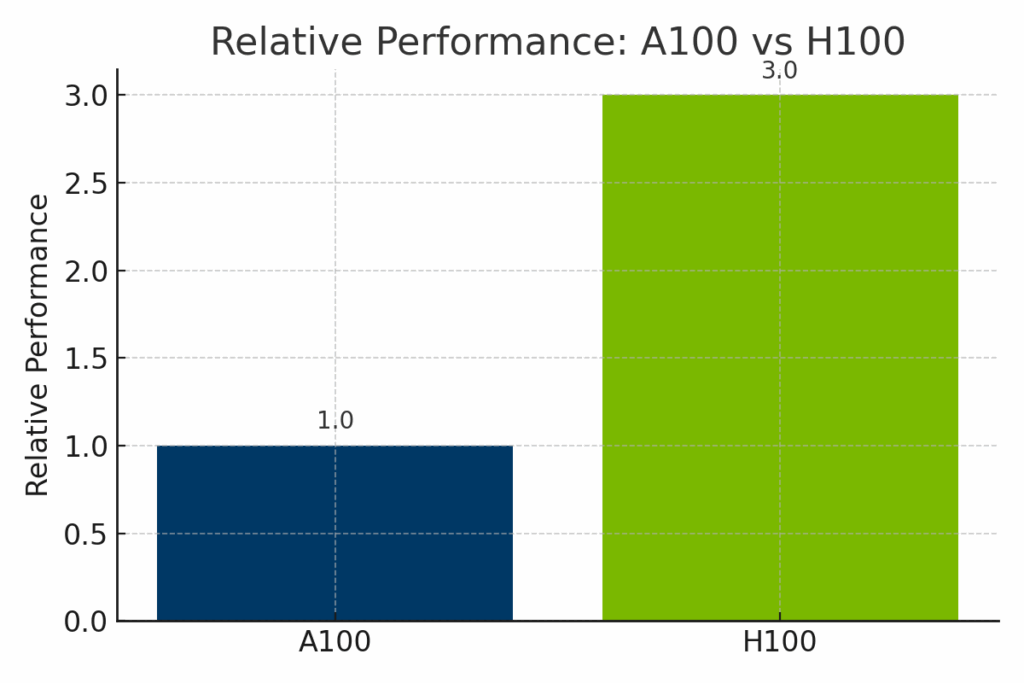
Figure : Valeur de revente estimée du NVIDIA A100 par rapport au H100 en 2025. Le H100 a un prix de revente nettement plus élevé - en moyenne autour de 130 000 TTP - en raison de son architecture plus récente et de ses performances de pointe, tandis que l'A100 se revend généralement entre 9 000 et 12 000 TTP.
Figure : Tarifs horaires de location dans le cloud pour les GPU A100 et H100 chez les principaux fournisseurs. Les instances H100 coûtent nettement plus cher - souvent autour de $3.00/heure - par rapport à la moyenne de $1.40/heure de l'A100, ce qui reflète l'amélioration du débit de l'IA de la H100 et la demande d'une infrastructure plus récente.
Figure : Performances normalisées de la NVIDIA A100 et de la H100 dans les charges de travail d'IA. Le H100 délivre jusqu'à 3 fois les performances de l'A100, en particulier dans les modèles basés sur les transformateurs et l'entraînement optimisé pour le FP8, ce qui le rend idéal pour l'IA d'entreprise à la pointe de la technologie.
Feuille de route et développements futurs de NVIDIA
L'avenir de NVIDIA cartes graphiques, basés sur l'architecture Blackwell à venir (par exemple, B100, B200), devraient offrir une densité de calcul et des améliorations de la mémoire encore plus importantes.
Les plates-formes logicielles de NVIDIA telles que CUDA, TensorRT et AI Enterprise sont activement mises à jour pour prendre en charge les nouvelles charges de travail.
Ecosystème logiciel et soutien aux développeurs
Les deux GPU sont pris en charge par CUDA, cuDNN, cuBLAS, TensorRT et des frameworks populaires tels que PyTorch, TensorFlow et JAX.
Le H100 bénéficie d'une meilleure prise en charge du FP8 et de l'optimisation du Transformer Engine au sein de ces écosystèmes. Les développeurs peuvent utiliser des conteneurs préconstruits sur NVIDIA NGC et une documentation solide via le NVIDIA Developer Program.
Résumé des avantages et des inconvénients
| Catégorie | NVIDIA A100 | NVIDIA H100 |
|---|---|---|
| Pour | Rentable, fiable, solide pour l'IA/HPC standard | Meilleure performance, FP8, supérieur pour les LLM et l'inférence en temps réel |
| Cons | Absence de nouvelles fonctionnalités d'IA (par exemple, FP8, Transformer Engine) | Coût plus élevé, forte consommation d'énergie, peut nécessiter une mise à niveau de l'infrastructure |
| Idéal pour | Équipes soucieuses de leur budget, calcul haute performance traditionnel, mise à l'échelle de l'informatique dématérialisée | Charges de travail d'IA de pointe, IA générative, déploiements en entreprise |
Choix entre A100 et H100 pour les charges de travail d'IA
Le choix entre l'A100 et le H100 dépend de vos objectifs, de votre budget et de votre cas d'utilisation. L'A100 est rentable tout en restant puissant pour de nombreuses tâches d'IA/HPC. La H100 est une centrale prête pour l'avenir, conçue pour les charges de travail les plus exigeantes.
Si vous passez à un GPU plus récent comme le H100, envisagez de vendre votre matériel existant à exIT Technologies. Les entreprises qui mettent hors service des serveurs à forte densité de GPU dans le cadre de ces mises à niveau peuvent également vendre des serveurs d'occasion pour récupérer un budget supplémentaire. Nous proposons des services de récupération des actifs sûrs et efficaces qui vous aident à récupérer la valeur et à gérer de manière responsable votre infrastructure mise hors service.
