La comunidad tecnológica sigue cautivada por la actual batalla entre titanes de la GPU en la alta computación (HPC), donde la velocidad y la eficiencia son primordiales. En la vanguardia de esta feroz competición, las GPU Tensor Core de NVIDIA han revolucionado el panorama, ampliando los límites de la capacidad de cálculo y abriendo nuevos horizontes para la investigación científica, la inteligencia artificial y las aplicaciones de gran volumen de datos.
En este blog, nos adentramos en el apasionante enfrentamiento entre dos destacadas GPU NVIDIA, la A100 y la H100, arrojando luz sobre sus capacidades únicas y explorando la importancia de su comparación. Estas GPU de última generación han redefinido las posibilidades de la alta computación, aprovechando tecnologías avanzadas para proporcionar un rendimiento y una escalabilidad sin precedentes.
Tabla comparativa de especificaciones técnicas de NVIDIA A100 vs H100
| Característica | NVIDIA A100 | NVIDIA H100 |
|---|---|---|
| Arquitectura | Amperios | Tolva |
| Núcleos CUDA | 6,912 | 18,432 |
| Núcleos tensores | 432 (3ª generación) | 640 (4ª generación) con Transformer Engine |
| Memoria | 40 GB / 80 GB HBM2e | 80 GB HBM3 |
| Ancho de banda de memoria | 2,0 TB/s | 3,35 TB/s |
| Rendimiento de FP32 | ~19,5 TFLOPS | ~51 TFLOPS |
| Rendimiento FP8 | No se admite | Más de 2.000 TFLOPS |
| NVLink | NVLink 3.0 (600 GB/s) | NVLink 4.0 (900 GB/s) |
| GPU multiinstancia (MIG) | MIG de 1ª generación (hasta 7 instancias) | MIG de 2ª generación |
| Consumo de energía PCIe | ~250W | ~350W |
| Consumo de energía SXM | ~400W | ~700W |
Especificaciones y funciones de NVIDIA A100
La NVIDIA A100, basada en la arquitectura Ampere, ofrece importantes avances con respecto a la anterior generación Volta. Equipada con 6.912 núcleos CUDA, 432 Tensor Cores de tercera generación y 40 GB u 80 GB de memoria HBM2e de alto ancho de banda, la A100 está diseñada para cargas de trabajo de IA de alto rendimiento. Ofrece hasta 20 veces más rendimiento que las GPU anteriores en tareas específicas de precisión mixta.
Los resultados de pruebas comparativas ponen de relieve su fortaleza en aplicaciones de aprendizaje profundo, como el reconocimiento de imágenes, el procesamiento del lenguaje natural (PLN) y el reconocimiento del habla.
Una innovación clave de la arquitectura Ampere es su tercera generación de Tensor Cores, optimizados para operaciones matriciales de alto rendimiento utilizando formatos como TF32 y FP16. La A100 también introduce la tecnología NVIDIA Multi-Instance GPU (MIG), que permite particionar una única GPU en hasta siete instancias aisladas.
Especificaciones y funciones de NVIDIA H100
La GPU NVIDIA H100, basada en la arquitectura Hopper, ofrece un rendimiento de vanguardia para cargas de trabajo de IA y HPC. Cuenta con 18.432 núcleos CUDA, 640 núcleos tensoriales de cuarta generación y 80 multiprocesadores de streaming (SM). El H100 proporciona hasta 51 teraflops de rendimiento FP32 y más de 2.000 teraflops utilizando precisión FP8.
Integra NVLink 4.0 para proporcionar hasta 900 GB/s de ancho de banda GPU-GPU y admite cargas de trabajo de última generación, como grandes modelos lingüísticos y redes neuronales profundas.
En las pruebas comparativas del sector, como MLPerf, la H100 supera significativamente a la A100 y la V100.
Comparación del rendimiento (MLPerf o basado en la carga de trabajo)
| Tipo de carga de trabajo | Rendimiento A100 | Rendimiento del H100 | Mejora |
|---|---|---|---|
| Inferencia BERT | 1× | 3.5-4× | Hasta 4× |
| Formación GPT-3 | 1× | 2-3× | 2-3× |
| Formación ResNet-50 | 1× | 2.2× | 2.2× |
| Simulación científica (FP64) | 1× | 2× | 2× |
Diferencias arquitectónicas entre A100 y H100
La A100 utiliza memoria HBM2e (40/80 GB) con un ancho de banda de 2,0 TB/s. La H100 sube a HBM3 (80 GB) y 3,35 TB/s de ancho de banda. El H100 incluye Tensor Cores de cuarta generación y precisión FP8, impulsados por un Transformer Engine.
Ambos admiten MIG, pero el MIG de 2ª generación de H100 ofrece mejor aislamiento y eficacia.
Comparación de la eficiencia energética
La GPU H100 consume más energía que la A100: hasta 700 W en el formato SXM frente a los 400 W de la A100. Sin embargo, este mayor consumo va acompañado de una mejora significativa del rendimiento, especialmente en las cargas de trabajo optimizadas para la precisión FP8 y el motor Transformer Engine.
Cuando se compara el rendimiento por vatio utilizando pruebas de referencia estandarizadas como MLPerf (por ejemplo, entrenamiento de ResNet-50), el H100 ofrece aproximadamente 60% más de eficiencia que el A100. Esto significa que, aunque el H100 consume más energía, también realiza más trabajo por unidad de potencia consumida.
En cuanto a la refrigeración, el H100 requiere una gestión térmica más robusta debido a su mayor densidad de potencia, pero los centros de datos modernos suelen estar equipados para ello. El aumento de la eficiencia justifica los requisitos de refrigeración adicionales en entornos de rendimiento crítico.
Escenarios de los mejores casos de uso (vista de tabla)
| Tipo de caso de uso | La mejor elección | Por qué |
|---|---|---|
| Formación general en aprendizaje profundo | A100 | Gran rendimiento y rentabilidad |
| Formación de grandes modelos lingüísticos | H100 | FP8 + Transformer Engine, excelente rendimiento |
| Inferencia en tiempo real | H100 | Acceso rápido y de baja latencia a la memoria |
| Simulaciones científicas | H100 | Mejor FP64 y ancho de banda |
| Proyectos de IA con presupuesto ajustado | A100 | Más asequible, ampliamente disponible |
| Entornos multiusuario | Ambos | H100 tiene mejor MIG; A100 es más económico |
Comparación de precios y disponibilidad A100 Vs H100
Aunque el H100 supera claramente al A100 en términos de potencia computacional bruta, también conlleva un coste significativamente superior, tanto en términos de valor de reventa del hardware como de tarifas horarias de alquiler en la nube. Para ayudar a ilustrar las compensaciones entre coste y capacidad, las siguientes comparaciones visuales desglosan cómo se comparan el A100 y el H100 en tres dimensiones clave: precio de reventa en el mercado, costes de implantación en la nube y rendimiento normalizado de la IA.
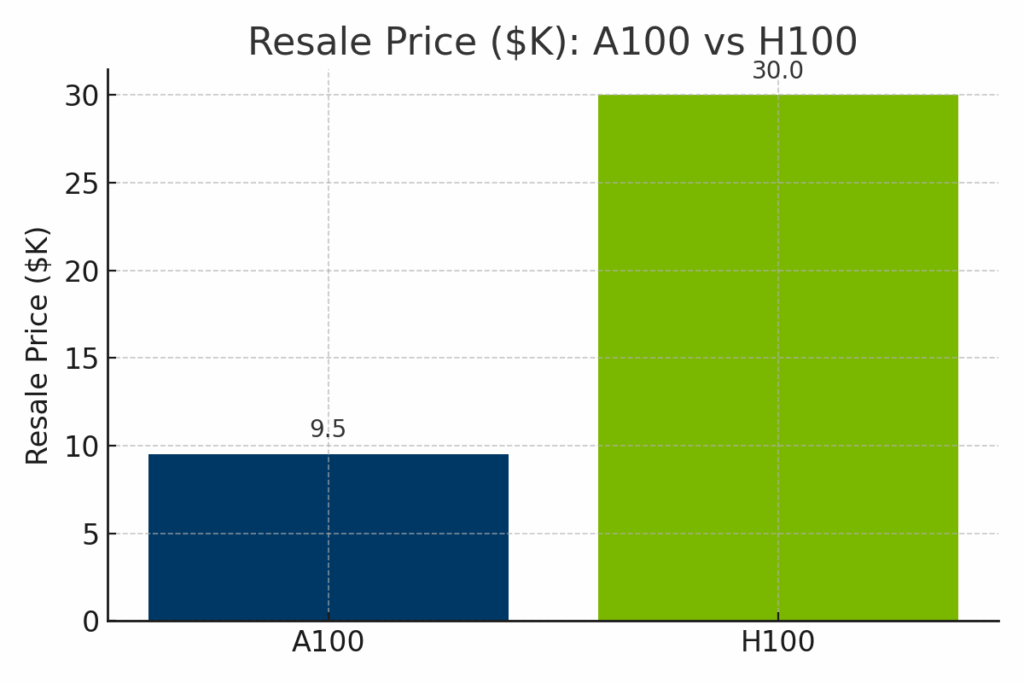
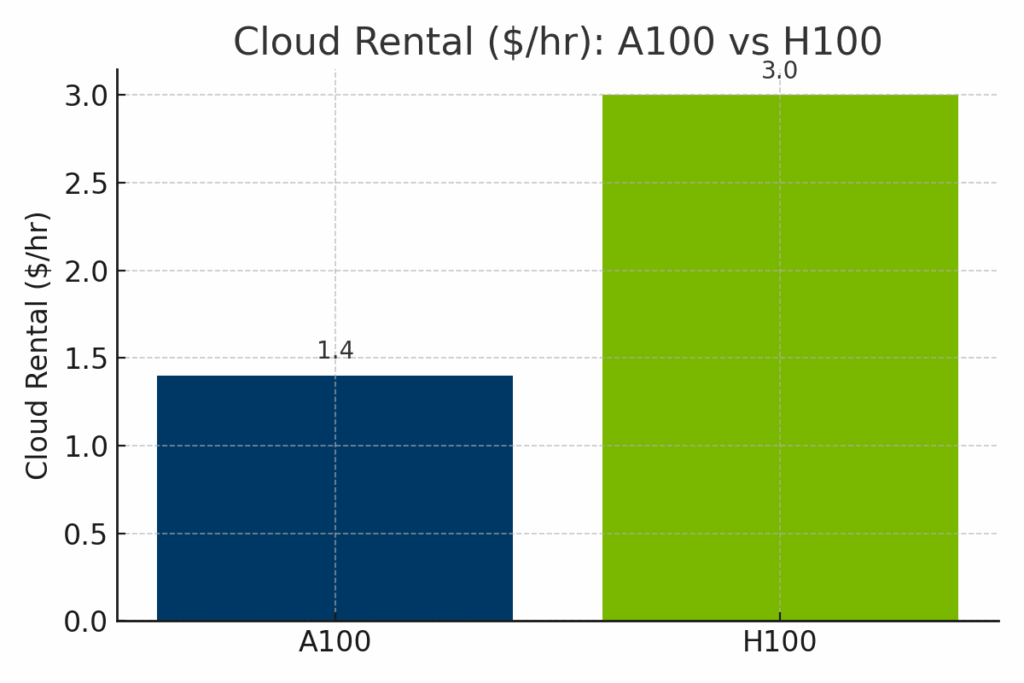
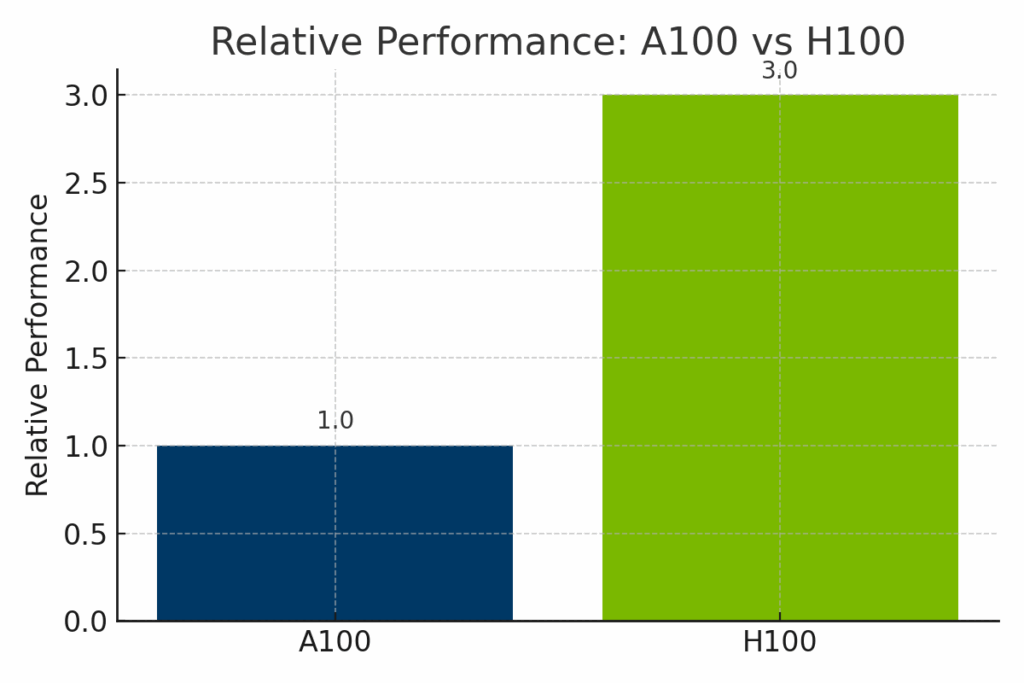
Figura: Valor de reventa estimado de la NVIDIA A100 frente a la H100 en 2025. El H100 tiene un precio de reventa mucho más elevado (en torno a los 1.400 millones de euros) debido a su arquitectura más reciente y su rendimiento de vanguardia, mientras que el A100 suele venderse por entre 1.400 y 1.400 millones de euros.
Figura: Tarifas horarias de alquiler en la nube de las GPU A100 y H100 en los principales proveedores. Las instancias H100 cuestan bastante más -a menudo alrededor de $3,00/hora- que las A100, que cuestan $1,40/hora de media, lo que refleja el mayor rendimiento de IA de las H100 y la mayor demanda de infraestructura.
Figura: Rendimiento normalizado de NVIDIA A100 y H100 en las cargas de trabajo de IA. La H100 ofrece hasta 3 veces más rendimiento que la A100, especialmente en modelos basados en transformadores y entrenamiento optimizado para FP8, lo que la hace ideal para la IA empresarial de vanguardia.
Hoja de ruta y desarrollos futuros de NVIDIA
Se espera que las futuras GPU de NVIDIA, basadas en la próxima arquitectura Blackwell (por ejemplo, B100, B200), proporcionen aún más densidad de cálculo y mejoras en la memoria.
Las plataformas de software de NVIDIA como CUDA, TensorRT y AI Enterprise se mantienen activamente para soportar nuevas cargas de trabajo.
Ecosistema de software y apoyo a los desarrolladores
Ambas GPU son compatibles con CUDA, cuDNN, cuBLAS, TensorRT y marcos de trabajo populares como PyTorch, TensorFlow y JAX.
H100 se beneficia del soporte mejorado de FP8 y la optimización de Transformer Engine dentro de estos ecosistemas. Los desarrolladores pueden utilizar contenedores preconstruidos en NVIDIA NGC y una sólida documentación a través del Programa para desarrolladores de NVIDIA.
Resumen de pros y contras
| Categoría | NVIDIA A100 | NVIDIA H100 |
|---|---|---|
| Pros | Rentable, fiable y resistente para IA/HPC estándar | Mejor rendimiento, FP8, superior para LLM e inferencia en tiempo real |
| Contras | Carece de las nuevas funciones de IA (por ejemplo, FP8, Transformer Engine) | Mayor coste, consumo intensivo de energía, puede necesitar una actualización de la infraestructura |
| Ideal para | Equipos con presupuesto limitado, HPC tradicional, escalado en la nube | Cargas de trabajo de IA de vanguardia, IA generativa, implantaciones en empresas |
Elegir entre A100 y H100 para cargas de trabajo de IA
Elegir entre el A100 y el H100 depende de tus objetivos, presupuesto y caso de uso. A100 es rentable y potente para muchas tareas de IA/HPC. H100 es una potencia preparada para el futuro y diseñada para las cargas de trabajo más exigentes.
Si está actualizando a una GPU más reciente como la H100, considere la posibilidad de vender su hardware heredado a exIT Technologies. Ofrecemos servicios de recuperación de activos seguros y eficientes que le ayudan a recuperar valor y a gestionar de forma responsable su infraestructura retirada.