Die Tech-Community ist nach wie vor fasziniert von dem anhaltenden Kampf zwischen den GPU-Titanen im High-Performance-Computing (HPC), wo Geschwindigkeit und Effizienz an erster Stelle stehen. An der Spitze dieses harten Wettbewerbs haben NVIDIAs Tensor Core GPUs die Landschaft revolutioniert, indem sie die Grenzen der Rechenleistung verschoben und neue Horizonte für wissenschaftliche Forschung, künstliche Intelligenz und datenintensive Anwendungen eröffnet haben.
In diesem Blog befassen wir uns mit dem spannenden Kräftemessen zwischen zwei bekannten NVIDIA-GPUs, dem A100 und dem H100, und beleuchten ihre einzigartigen Fähigkeiten sowie die Bedeutung ihres Vergleichs. Diese hochmodernen Grafikprozessoren haben die Möglichkeiten im HPC-Bereich neu definiert. Sie nutzen fortschrittliche Technologien, um eine noch nie dagewesene Leistung und Skalierbarkeit zu bieten.
Vergleichstabelle der technischen Daten zwischen NVIDIA A100 und H100
| Merkmal | NVIDIA A100 | NVIDIA H100 |
|---|---|---|
| Architektur | Ampere | Trichter |
| CUDA Kerne | 6,912 | 18,432 |
| Tensor-Kerne | 432 (3. Generation) | 640 (4. Generation) mit Transformer Engine |
| Speicher | 40 GB / 80 GB HBM2e | 80 GB HBM3 |
| Speicher-Bandbreite | 2,0 TB/s | 3,35 TB/s |
| FP32 Leistung | ~19,5 TFLOPS | ~51 TFLOPS |
| FP8 Leistung | Nicht unterstützt | Über 2.000 TFLOPS |
| NVLink | NVLink 3.0 (600 GB/s) | NVLink 4.0 (900 GB/s) |
| Multi-Instanz-GPU (MIG) | 1st Gen MIG (bis zu 7 Instanzen) | MIG der 2. Generation |
| PCIe-Leistungsaufnahme | ~250W | ~350W |
| SXM Stromverbrauch | ~400W | ~700W |
NVIDIA A100 Technische Daten und Leistungsmerkmale
Der NVIDIA A100, der auf der Ampere-Architektur basiert, bietet bedeutende Fortschritte gegenüber der vorherigen Volta-Generation. Ausgestattet mit 6.912 CUDA-Kernen, 432 Tensor-Cores der dritten Generation und 40 GB oder 80 GB HBM2e-Speicher mit hoher Bandbreite ist der A100 für leistungsstarke KI-Workloads konzipiert. Sie bietet eine bis zu 20-mal schnellere Leistung im Vergleich zu früheren GPUs bei bestimmten Mixed-Precision-Aufgaben.
Benchmark-Ergebnisse unterstreichen seine Stärke bei Deep-Learning-Anwendungen, einschließlich Bilderkennung, Verarbeitung natürlicher Sprache (NLP) und Spracherkennung.
Eine wichtige Innovation der Ampere-Architektur sind die Tensor-Cores der dritten Generation, die für Matrixoperationen mit hohem Durchsatz in Formaten wie TF32 und FP16 optimiert sind. Der A100 führt auch die NVIDIA Multi-Instance GPU (MIG) Technologie ein, die es ermöglicht, eine einzelne GPU in bis zu sieben isolierte Instanzen zu partitionieren.
NVIDIA H100 Technische Daten und Funktionen
Der NVIDIA H100 Grafikprozessor, der auf der Hopper-Architektur basiert, bietet Spitzenleistung für KI- und HPC-Workloads. Er verfügt über 18.432 CUDA-Kerne, 640 Tensor-Cores der vierten Generation und 80 Streaming-Multiprozessoren (SMs). Der H100 bietet bis zu 51 Teraflops an FP32-Leistung und über 2.000 Teraflops bei FP8-Präzision.
Sie integriert NVLink 4.0 für bis zu 900 GB/s GPU-zu-GPU-Bandbreite und unterstützt Workloads der nächsten Generation wie große Sprachmodelle und tiefe neuronale Netzwerke.
In Branchenbenchmarks wie MLPerf schneidet der H100 deutlich besser ab als der A100 und der V100.
Benchmark-Vergleich der Leistung (MLPerf oder Workload-basiert)
| Arbeitsbelastung Typ | A100 Leistung | H100 Leistung | Verbesserung |
|---|---|---|---|
| BERT-Inferenz | 1× | 3.5-4× | Bis zu 4× |
| GPT-3 Ausbildung | 1× | 2-3× | 2-3× |
| ResNet-50-Schulung | 1× | 2.2× | 2.2× |
| Wissenschaftliche Simulation (FP64) | 1× | 2× | 2× |
Architektonische Unterschiede zwischen A100 und H100
Der A100 verwendet HBM2e-Speicher (40/80 GB) mit einer Bandbreite von 2,0 TB/s. Der H100 steigt auf HBM3 (80 GB) und 3,35 TB/s Bandbreite auf. Der H100 enthält Tensor-Cores der vierten Generation und FP8-Präzision, angetrieben von einer Transformer Engine.
Beide unterstützen MIG, aber das MIG der 2. Generation des H100 bietet eine bessere Isolierung und Effizienz.
Vergleich der Leistungseffizienz
Die H100-GPU verbraucht mehr Strom als die A100 - bis zu 700 W im SXM-Formfaktor gegenüber 400 W bei der A100. Diese höhere Leistungsaufnahme geht jedoch mit einer deutlich verbesserten Leistung einher, insbesondere bei Workloads, die für FP8-Präzision und die Transformer Engine optimiert sind.
Beim Vergleich der Leistung pro Watt mit standardisierten Benchmarks wie MLPerf (z. B. ResNet-50-Training) liefert der H100 eine um etwa 60% höhere Effizienz als der A100. Das bedeutet, dass der H100 zwar mehr Energie verbraucht, aber auch mehr Arbeit pro verbrauchter Leistungseinheit leistet.
Was die Kühlung betrifft, so erfordert der H100 aufgrund seiner höheren Leistungsdichte ein robusteres Wärmemanagement, aber moderne Rechenzentren sind im Allgemeinen dafür gerüstet. Die Effizienzgewinne rechtfertigen die zusätzlichen Kühlungsanforderungen in leistungskritischen Umgebungen.
Beste Anwendungsszenarien (Tabellenansicht)
| Anwendungsfall Typ | Beste Wahl | Warum |
|---|---|---|
| Allgemeines Deep Learning Training | A100 | Starke Leistung, kosteneffizient |
| Training eines großen Sprachmodells | H100 | FP8 + Transformer Engine, ausgezeichneter Durchsatz |
| Inferenz in Echtzeit | H100 | Niedrige Latenz, schneller Speicherzugriff |
| Wissenschaftliche Simulationen | H100 | Bessere FP64 und Bandbreite |
| Budgetbewusste AI-Projekte | A100 | Erschwinglicher, weithin verfügbar |
| Multi-Tenant-Umgebungen | Beide | H100 hat besseres MIG; A100 ist wirtschaftlicher |
Vergleich von Preis und Verfügbarkeit A100 vs. H100
Während die H100 die A100 in Bezug auf die reine Rechenleistung deutlich übertrifft, ist sie auch mit deutlich höheren Kosten verbunden - sowohl in Bezug auf den Wiederverkaufswert der Hardware als auch auf die stündlichen Cloud-Mietpreise. Um den Kompromiss zwischen Kosten und Leistung zu verdeutlichen, werden im folgenden visuellen Vergleich die A100 und die H100 in Bezug auf drei Schlüsseldimensionen aufgeschlüsselt: Wiederverkaufsmarktpreise, Cloud-Bereitstellungskosten und normalisierte KI-Leistung.
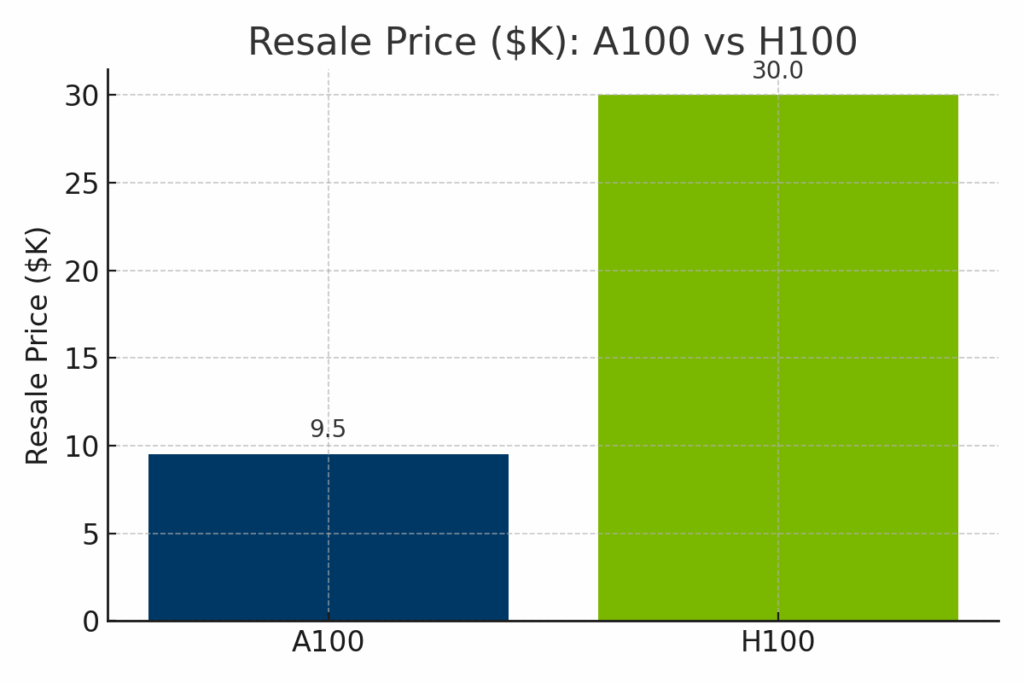
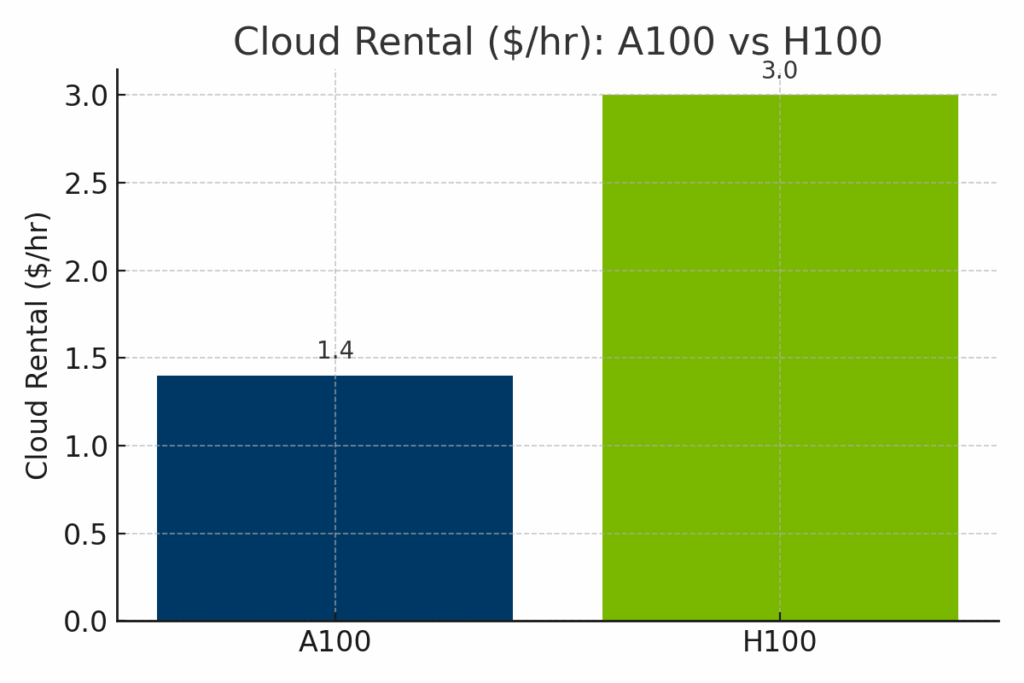
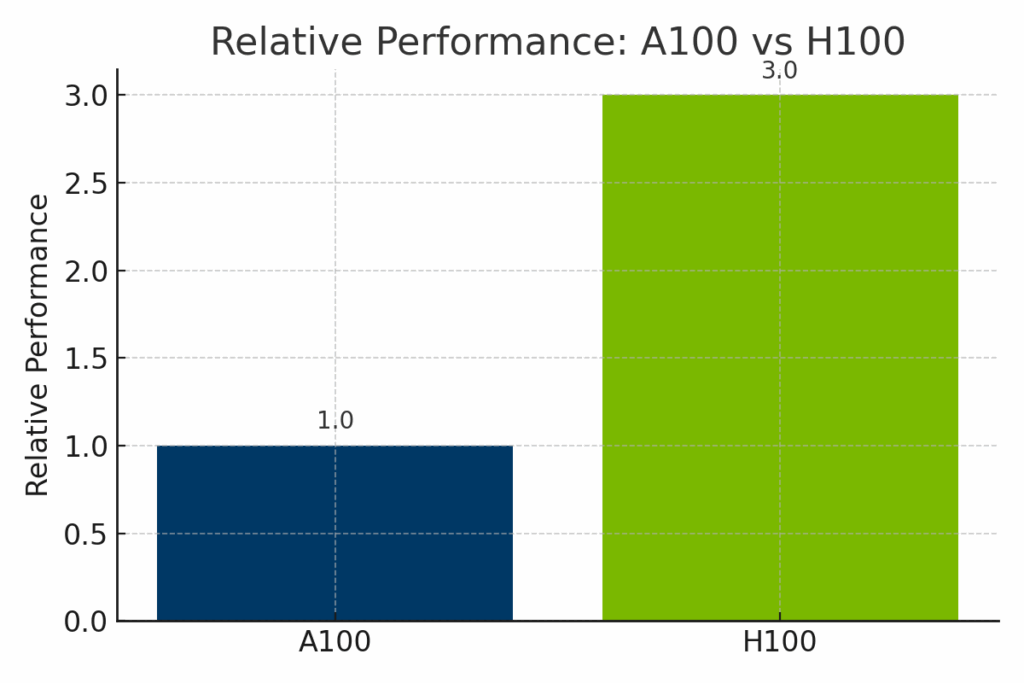
Abbildung: Geschätzter Wiederverkaufswert des NVIDIA A100 gegenüber dem H100 im Jahr 2025. Der H100 erzielt aufgrund seiner neueren Architektur und Spitzenleistung einen deutlich höheren Wiederverkaufspreis von durchschnittlich etwa $30.000, während der A100 in der Regel für $9.000-$12.000 weiterverkauft wird.
Abbildung: Stündliche Cloud-Mietpreise für A100- und H100-GPUs bei den wichtigsten Anbietern. H100-Instanzen kosten deutlich mehr - oft um die $3,00/Stunde - im Vergleich zu den durchschnittlichen $1,40/Stunde der A100, was den verbesserten KI-Durchsatz der H100 und den neueren Infrastrukturbedarf widerspiegelt.
Abbildung: Normalisierte Leistung des NVIDIA A100 und H100 bei KI-Workloads. Der H100 liefert bis zu dreimal mehr Leistung als der A100, insbesondere bei transformatorbasierten Modellen und FP8-optimiertem Training, und ist damit ideal für innovative KI in Unternehmen.
NVIDIA Roadmap und zukünftige Entwicklungen
Es wird erwartet, dass die zukünftigen NVIDIA-GPUs, die auf der kommenden Blackwell-Architektur (z. B. B100, B200) basieren, eine noch höhere Rechendichte und Speicherverbesserungen bieten werden.
NVIDIAs Software-Plattformen wie CUDA, TensorRT und AI Enterprise werden aktiv gewartet, um neue Workloads zu unterstützen.
Software-Ökosystem und Entwicklerunterstützung
Beide GPUs werden von CUDA, cuDNN, cuBLAS, TensorRT und gängigen Frameworks wie PyTorch, TensorFlow und JAX unterstützt.
H100 profitiert von der erweiterten FP8-Unterstützung und der Optimierung der Transformer Engine innerhalb dieser Ökosysteme. Entwickler können vorgefertigte Container auf NVIDIA NGC und robuste Dokumentation über das NVIDIA Developer Program nutzen.
Zusammenfassung der Vor- und Nachteile
| Kategorie | NVIDIA A100 | NVIDIA H100 |
|---|---|---|
| Profis | Kostengünstig, zuverlässig, leistungsstark für Standard-KI/HPC | Beste Leistung, FP8, überlegen für LLMs und Echtzeit-Inferenz |
| Nachteile | Fehlende neuere KI-Funktionen (z. B. FP8, Transformer Engine) | Höhere Kosten, stromintensiv, erfordert möglicherweise eine Aufrüstung der Infrastruktur |
| Ideal für | Budgetbewusste Teams, traditionelles HPC, Cloud-Skalierung | Modernste KI-Workloads, generative KI, Unternehmensbereitstellungen |
Die Wahl zwischen A100 und H100 für KI-Workloads
Die Entscheidung zwischen dem A100 und dem H100 hängt von Ihren Zielen, Ihrem Budget und Ihrem Anwendungsfall ab. Der A100 ist kosteneffizient und dennoch leistungsstark für viele AI/HPC-Aufgaben. Der H100 ist ein zukunftssicheres Kraftpaket für die anspruchsvollsten Workloads.
Wenn Sie auf einen neueren Grafikprozessor wie den H100 aufrüsten, sollten Sie den Verkauf Ihrer alten Hardware an exIT Technologies in Betracht ziehen. Wir bieten sichere und effiziente Asset-Recovery-Services, mit denen Sie den Wert Ihrer ausgemusterten Infrastruktur wiederherstellen und verantwortungsvoll verwalten können.